
Exploring Fibonacci Based Compression

Is there a way to compress data using Fibonacci numbers? When we look at nature, there are many emergent shapes that resemble a Fibonacci sequence and golden ratios, from sea shells to plants to spiral galaxies. Why does this pattern seem to pop up in nature so often?

This question bothered me. I mean, I could imagine that when stuff settles, it can’t help but fall into certain lower-energy patterns which then resemble self-repeating patterns like the Fibonacci series. And this process emerges, scaled up and down, throughout the universe. That makes sense. But could we possibly compress data with this idea? Could we “settle” data?
One way to think about this is to ask whether we could transform raw data from binary ones and zeroes to another, more compact sequence of ones and zeroes interchangeably without losing anything. There are already many compression algorithms out there that already do this that involve searching for common patterns in the input data and storing those patterns more compactly than the original data. But could we figure out an algorithm that uses Fibonacci numbers to shrink the data instead of searching the data for patterns?
One cool thing about the Fibonacci series is that any positive integer can be represented by a unique set of distinct, non-adjacent, Fibonacci numbers. This is called Zeckendorf’s Theorem. How would we represent an integer with these properties using binary ones and zeros? Let’s look at some simple examples. How about the number 12? Firstly, how is that number represented in regular binary? That’s 1100, which, for those unfamiliar with binary numbers, is 1*2^3 + 1*2^2 + 0*2^1 + 0*2^0 which is 8 + 4, or simply 12. See what we did there? Those “1”s in binary represent whether or not to include the corresponding power of 2.
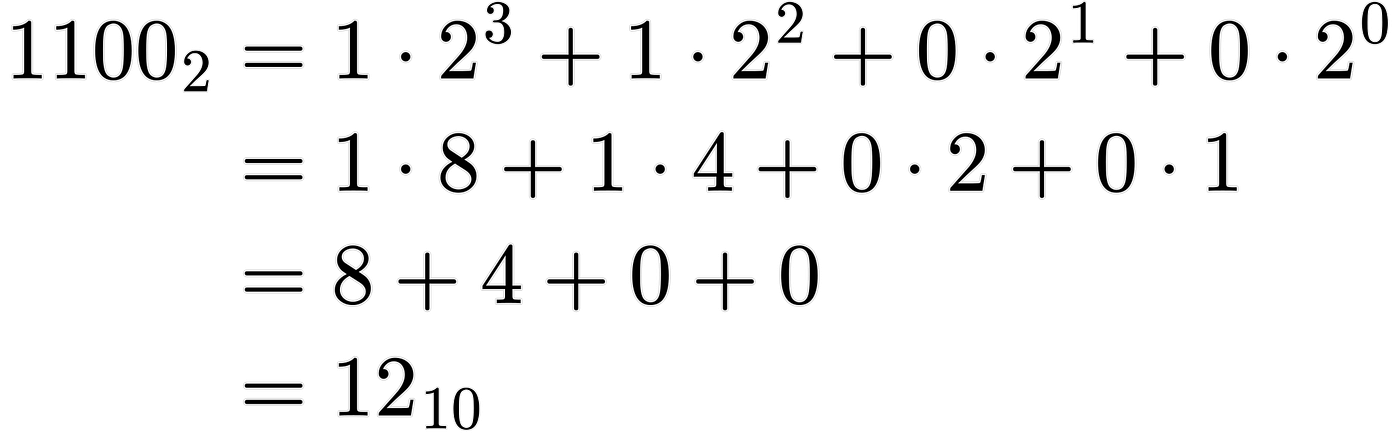
Ok, so how can we apply that to those unique properties of Fibonacci numbers? Let’s think again about the number 12. It took 4 bits to represent that number in binary. Could we do better? Let’s try to decompose 12 into a unique sequence of non repeating Fibonacci numbers. What is the largest Fibonacci number that fits into 12? 8. Ok, so we subtract 8 from 12 and we have 4 remaining. Now let’s do that process again. What’s the largest Fibonacci number that fits into 4? 3. Same thing: subtract 3 and we just get 1, our last Fibonacci number. The cool thing about this is that the number 12 was broken down into just 3 Fibonacci numbers. So, how does that help? Well, we can think of which Fibonacci numbers to utilize in order to sum up to our number we want to represent. If we want to include the Fibonacci term, we use a 1 in front of the corresponding Fibonacci number, and use 0 otherwise. So like binary, we can make a similar expression: 1*8 + 0*5 + 1*3 + 0*2 + 1*1 which equals 12. This expression is also an example of Fibbinary, where each bit tells whether or not to add the corresponding Fibonacci number, starting with 1, 2, 3, 5, 8, etc.
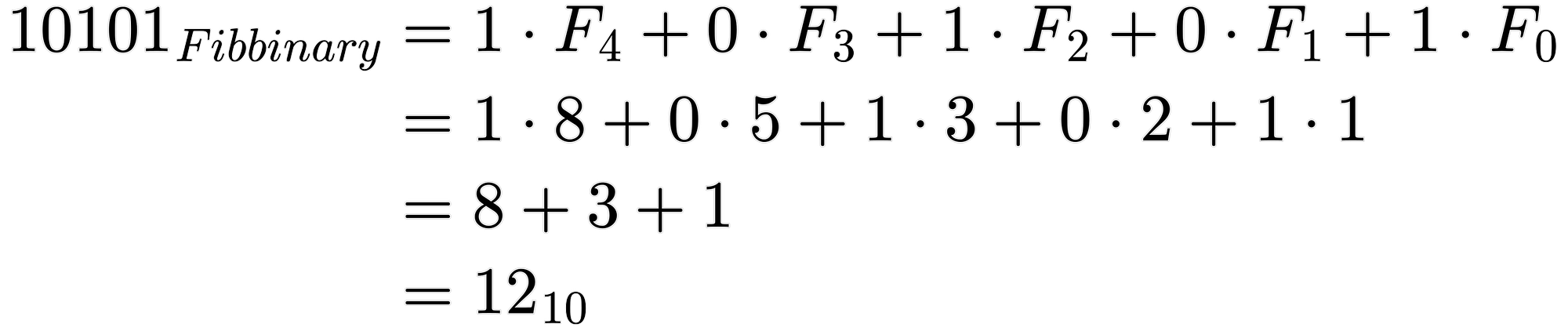
“But Peter!” You might say. “That uses 5 bits of information to represent using Fibonacci! It looks like 10101!” I hear you. But we’re not done! Do we need all those bits? No! And the reason is pretty simple. If we ever see a ‘1’, we know the next digit must be a ‘0’. This is because if there ever were two consecutive ‘1’ bits in a Fibbinary representation, then we might as well use the next Fibonacci number that’s composed of those two smaller, consecutive Fibonacci numbers. This means we can omit zeros that occur after ones. Our bit representation “knows” to skip adding any Fibonacci numbers after a ‘1’ is seen. So how would we represent the number 12 again, using, what I’ll refer to from here on out, as “Zeckendorf representation”? Well, we had 10101 with Fibbinary representation. And we can just drop those unnecessary zeros because the prior 1’s already tell us to skip those Fibonacci numbers. So we are left with 111! That’s just 3 bits! And in binary, it took us 4 bits to represent the number 12! So we just saved a whole bit! That’s a 25% reduction!
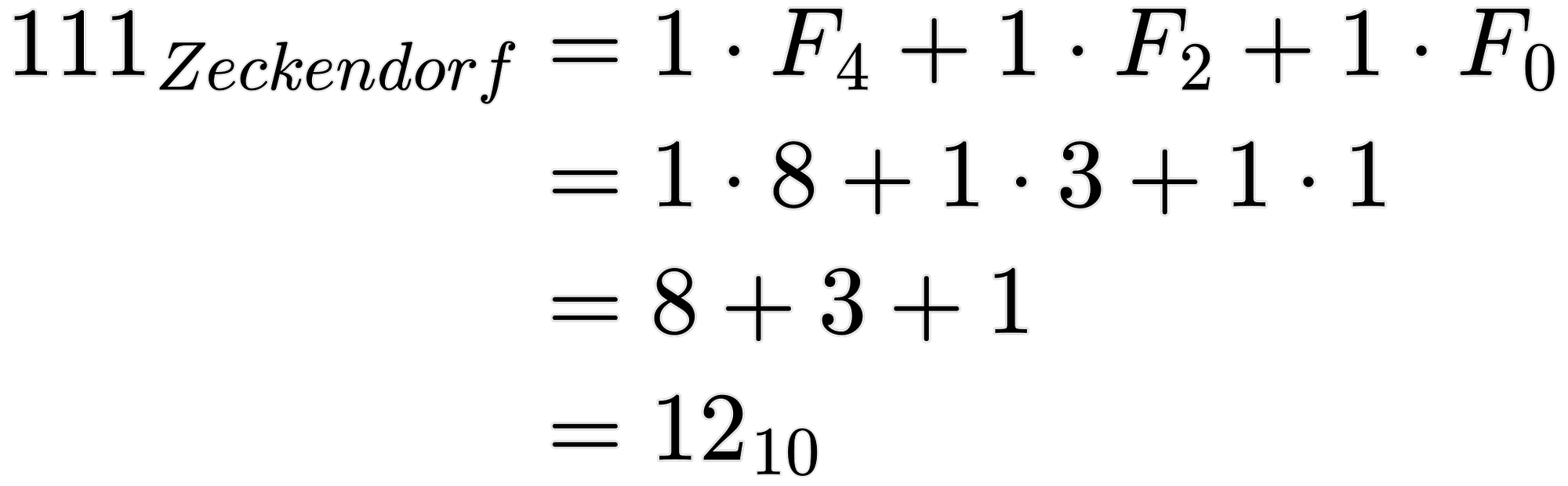
“But Peter, that’s just one bit! That’s not compression!” Well, technically it could be, if it scales to larger numbers. I’ve done some investigating and, unfortunately, it turns out that large numbers with smaller Zeckendorf representations are unlikely and there’s a limit to how good it can get. But this does allow us to more compactly represent numbers, and therefore, data, if it happens to fall on or close to a “well compressible number”.
What do I mean by a “well compressible” number? Well, we can think of the degenerate case where the Zeckendorf representation of the number is all 1’s, which can reach out to larger numbers “faster” than using binary representation, and each ‘1’ bit conveys more that 1 bit of classical binary information since it tells us the next digit to add cannot be the next Fibonacci number. For example, the binary number 11111111 is 8 ‘1’ bits. In binary, that represents the decimal number 255. But interpreting those 8 ‘1’ bits with Zeckendorf representation, it expands out to 1 + 3 + 8 + 21 + 55 + 144 + 377 + 987 = 1596, a much larger number than 255. And representing the decimal number 1596 as binary is “110 0011 1100”, which is 11 bits. So in this example, we were able to represent a number needing 11 binary bits with 8, a ~27% reduction.
Here are some graphs showing the ratio of bits necessary to represent numbers using Zeckendorf representation versus binary representation. The green line at 1.0 represents par compression; no benefit to using Zeckendorf representation. When the blue line dips below the green line, that demonstrates that the number on the x-axis had a Zeckendorf representation that used fewer bits than its binary representation. The following graph shows this compression ratio for numbers up to 1,000.
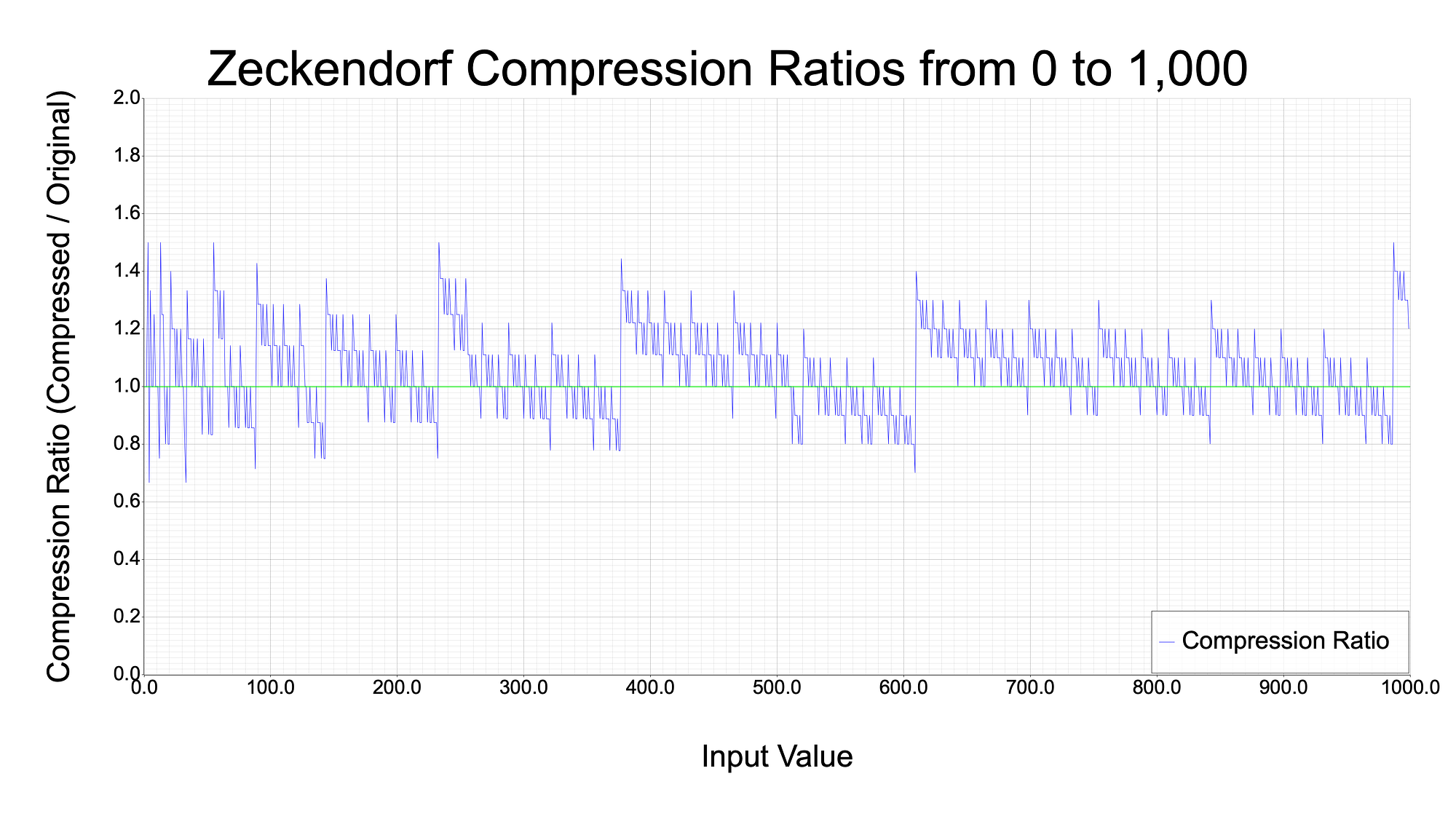
The graph below plots much more data, so it is easier to see interesting patterns for when the Zeckendorf representation was beneficial. Perhaps such patterns could be utilized to search for the optimal compression method. More on that later in the article.
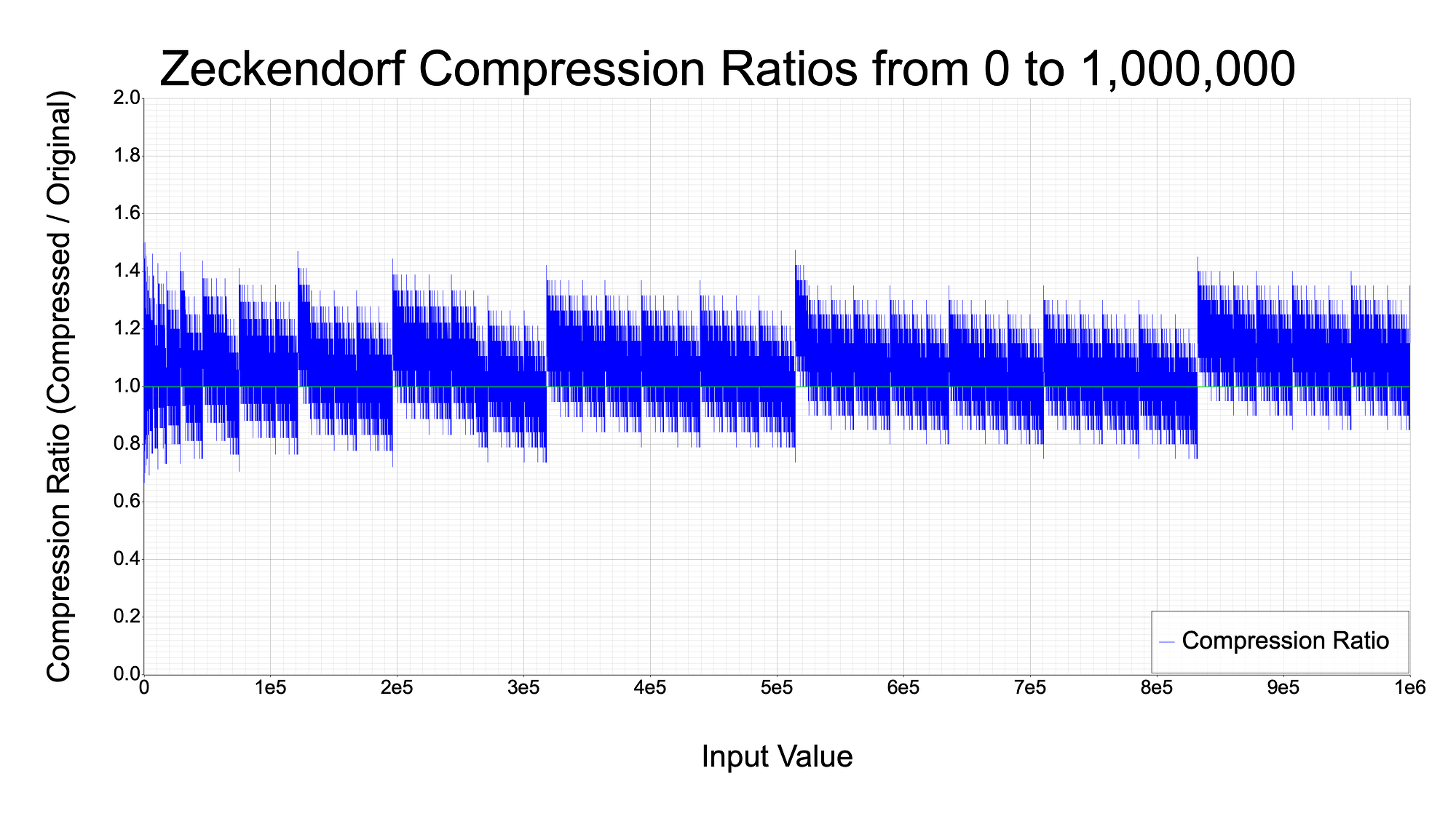
And just for fun, here is a graph for all numbers up to 100 million.
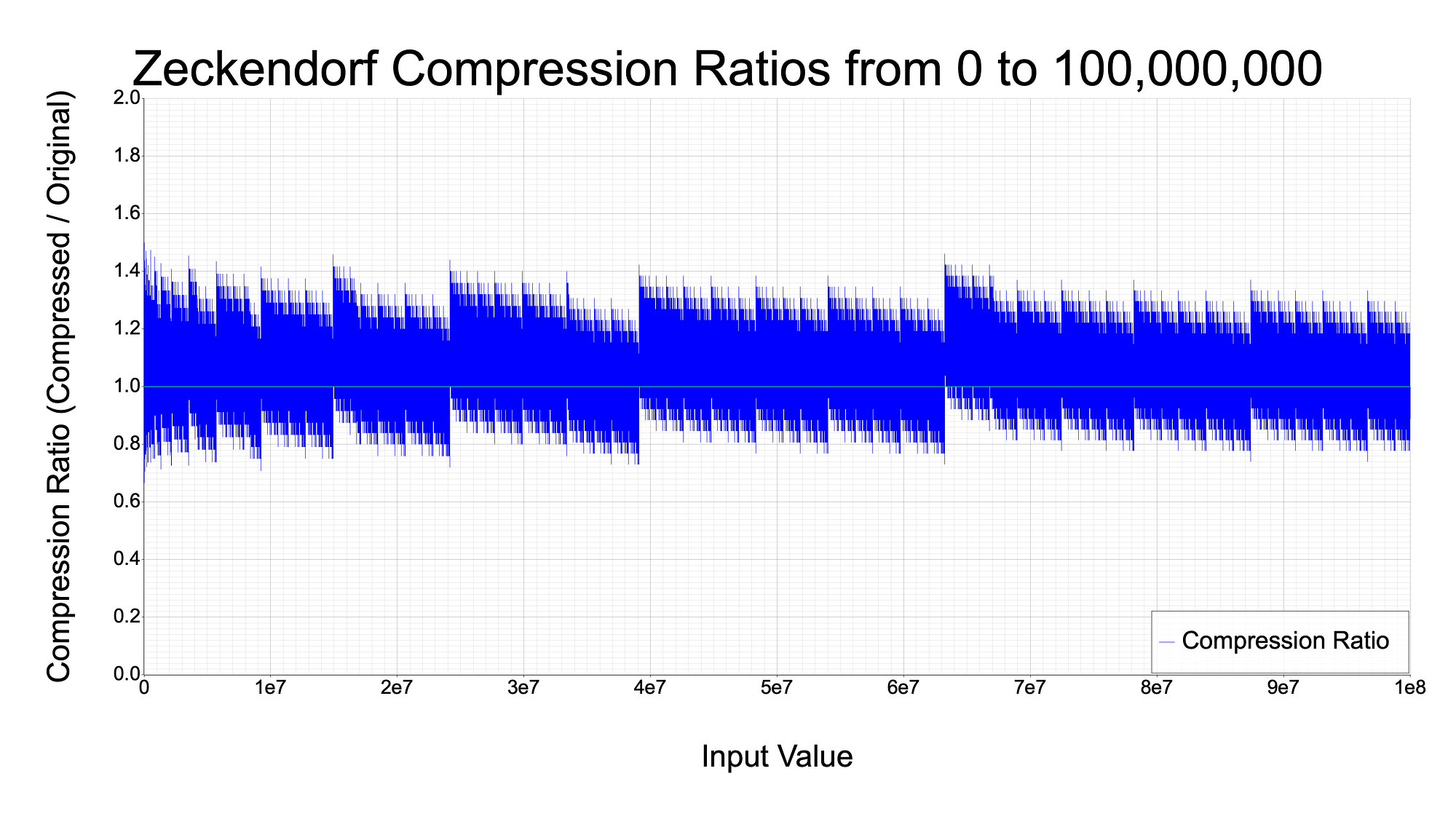
So, as you can see, there is some potential for using these numbers to compress data. The tradeoff is that you are not guaranteed to be able to compress your data. This can be seen by how thick the blue lines are above the green line at par, versus the lesser amount of blue below the par line. Later in this article, I’ll go over some statistics for how likely this actually is. TLDR: the odds are not great for data larger than 1kbit, unfortunately.
Why Does This Work?
It is strange to think that there exist large numbers that require less information to represent than smaller numbers. On the surface, it seems to break long-standing ideas in information theory. I mean, we’ve known about data compression for a long time which is essentially the same concept of certain larger “numbers” requiring less information than certain smaller ones. But this Zeckendorf based transformation of data feels like a different class of compression algorithm altogether. After all, it’s an extremely simple algorithm and does not really require any knowledge or inspection of the input bits unlike other compression algorithms. We are simply taking a string of bits, interpreting it as a number, and representing it as a different string of bits.
My attempt at making this intuitive is to say that “representing a number with Zeckendorf bits produces a shorter string of bits if the input data was composed of lots of Fibonacci numbers.” The more Fibonacci numbers that the input was composed of, the better it can be “compressed”. The extreme case here is having a Zeckendorf number where all bits are 1. Later in the article, I will do some inspection on these numbers, which I will call “All Ones Zeckendorf Numbers”, or AOZNs. The extreme opposite case is having a number composed of only 1 Fibonacci number, so the string of Zeckendorf bits is mostly zeroes and one 1. I’ll call these numbers “poorly compressible”, with respect to Zeckendorf compression.
Since a number is better compressible if it is composed of many Fibonacci numbers, maybe we can make a connection here to the real world, where golden ratios and spirals emerge that are also composed of Fibonacci numbers. I haven’t settled on a term for this, but perhaps we can call it “settling” or a “settled number”, pun intended.
Zeckendorf Compression
I propose a couple standards for Zeckendorf based compression.
The Padless Zeckendorf Compression algorithm is essentially treating the input data as a big integer and then representing this big integer with Zeckendorf bits. I call it padless because when decompressing, if you don’t know the original file size, you might lose leading zeroes which should have been padded, because they were effectively dropped when interpreting the input data as an integer. Therefore, this is a lossy compression algorithm. The Padded Zeckendorf Compression algorithm retains the original size of the data in the output format, so that it can pad the decompressed output with leading zeroes. This loses some compression efficiency because, now, we need to store the original file size along with the compressed data, but it is lossless.
I have an MIT licensed open source implementation for these in Rust at https://github.com/pRizz/zeckendorf, so anyone can play around with it. I have published a Rust crate of this library, called zeck, and a corresponding WASM compiled npm package called zeck.
I also created a basic demo web application, which uses the WASM compiled Rust code, to compress and decompress files losslessly by simply dragging and dropping. The website will tell you if the transformed data was or wasn’t smaller than the original. I have open sourced it on GitHub. As of now, the algorithm requires improvement, because attempting to compress or decompress files larger than about 10kBits requires generating, caching, and dealing with Fibonacci numbers that are > 10,000 bits long, which causes memory issues. That’s an astoundingly large number when you think about it: 2¹⁰⁰⁰⁰. For reference, the number 1 trillion only takes about 40 bits to represent. One of the largest named numbers is a centillion, which represents 10³⁰³ and takes only about 1,000 bits to represent. So we’re dealing with some pretty astronomical Fibonacci numbers here!
Performance of Padless Zeckendorf Compression
This compression is probabilistic, meaning it is not guaranteed to compress data since most Zeckendorf representations of integers require more bits than the input data. This is evident in the graphs above, where a majority of the blue lines are above the green line at par. Since it it probabilistic, I have generated some very basic statistics for how well or poorly this Zeckendorf compression algorithm performs at compressing data.
After testing, I discovered that there is a pretty steep drop in the odds of any random data being favorably compressible after the input data increases larger than a few hundred bits. Here is a graph demonstrating this falloff.
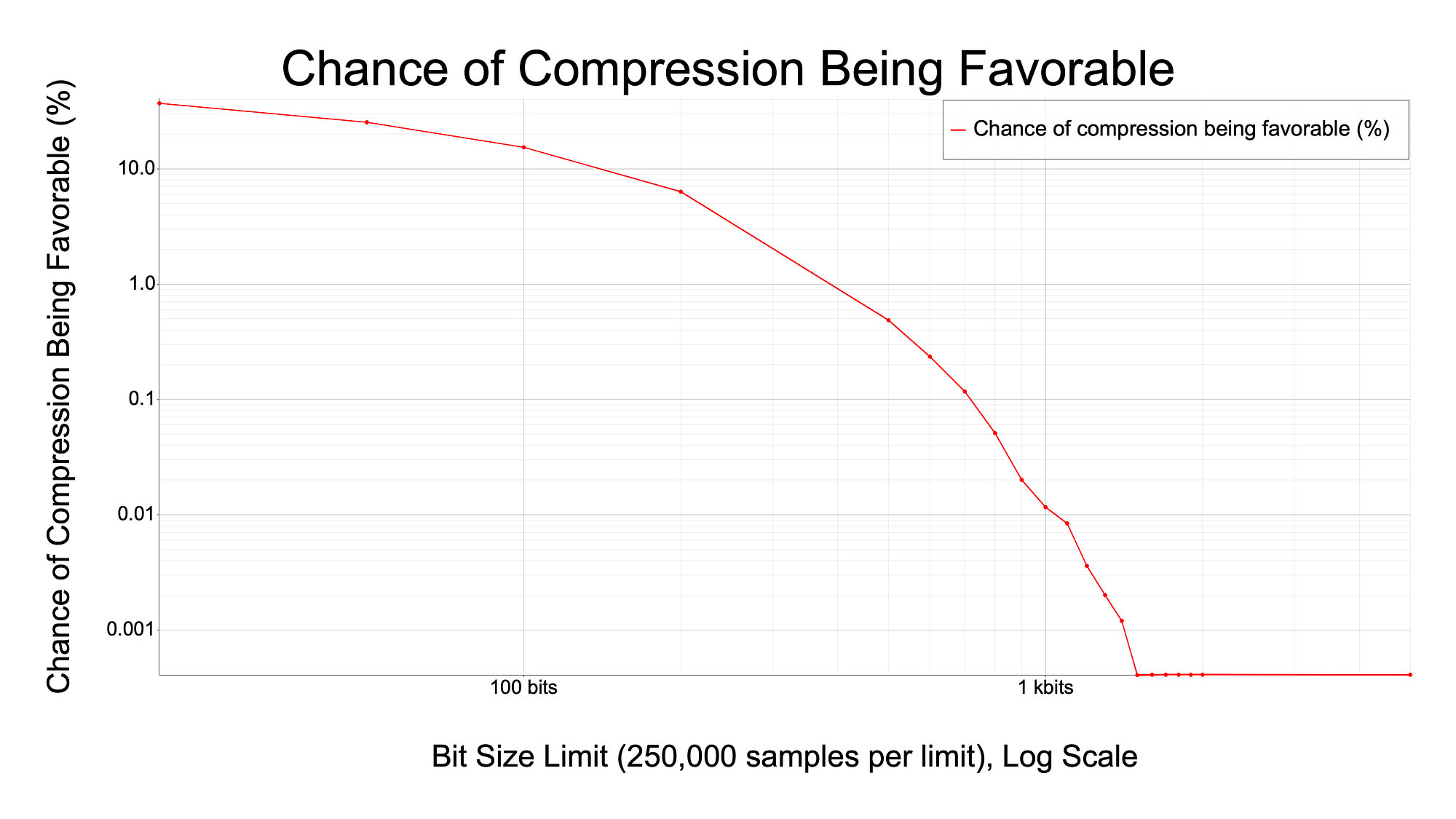
Early on in the graph, you can see that there is a decent chance of the data being smaller after being compressed, between 10–15% chance. But as the size of the input data grows, the graph collapses approaching a 0% chance of being compressible after around 1 kbit. Some examples for the way to interpret this graph are: if you supply 100 bits of random data, there is a ~10% chance of the output being smaller than 100 bits. If you supply 1 kbit of random data, there is only a ~0.01% chance of the output being smaller than 1 kbit.
Beyond that, it would be interesting to see how well the data does get compressed if it happens to be favorable. That is what I try to show with the graph below. It shows a number of different series based on compressing all inputs up to the value shown on the x-axis. For example, the dot on the x-axis at 1e5, means the corresponding y values used all numbers individually, up to 100,000, for compression. These scales are quite small, but they are comprehensive, in that all numbers up to the input limit were compressed. The reason I don’t go much higher is that it took very long (~20 minutes) to generate data on compressing all numbers up to 100 million, and the returns diminish as the data gets larger.
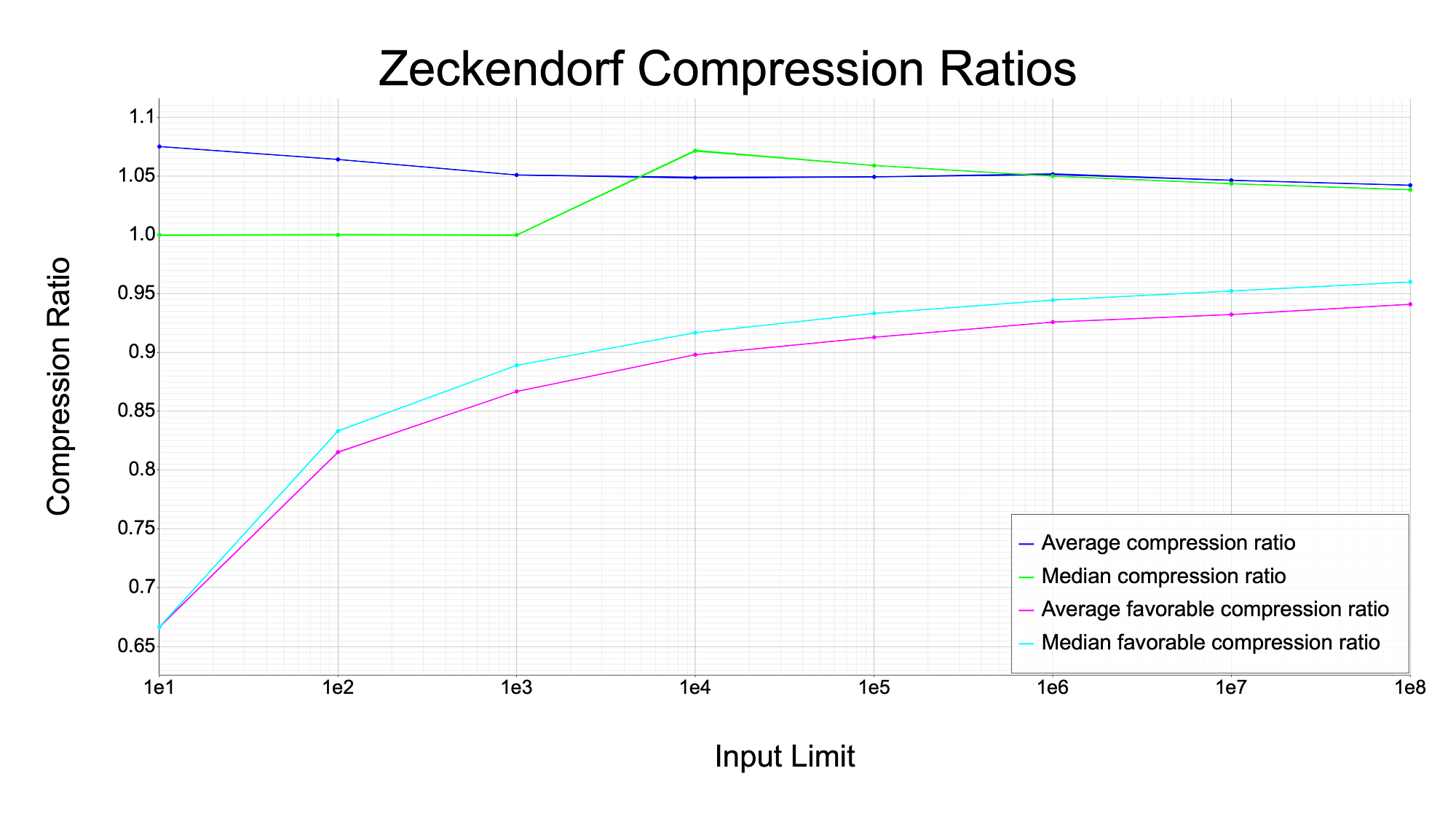
Unfortunately, this graph does not test very large scales; the number 1e8 is 100 million, which only takes about 27 bits to represent. The graph below zooms out and shows the average and median compression ratios up to 5 kbits, using 250,000 random samples at each input data size.
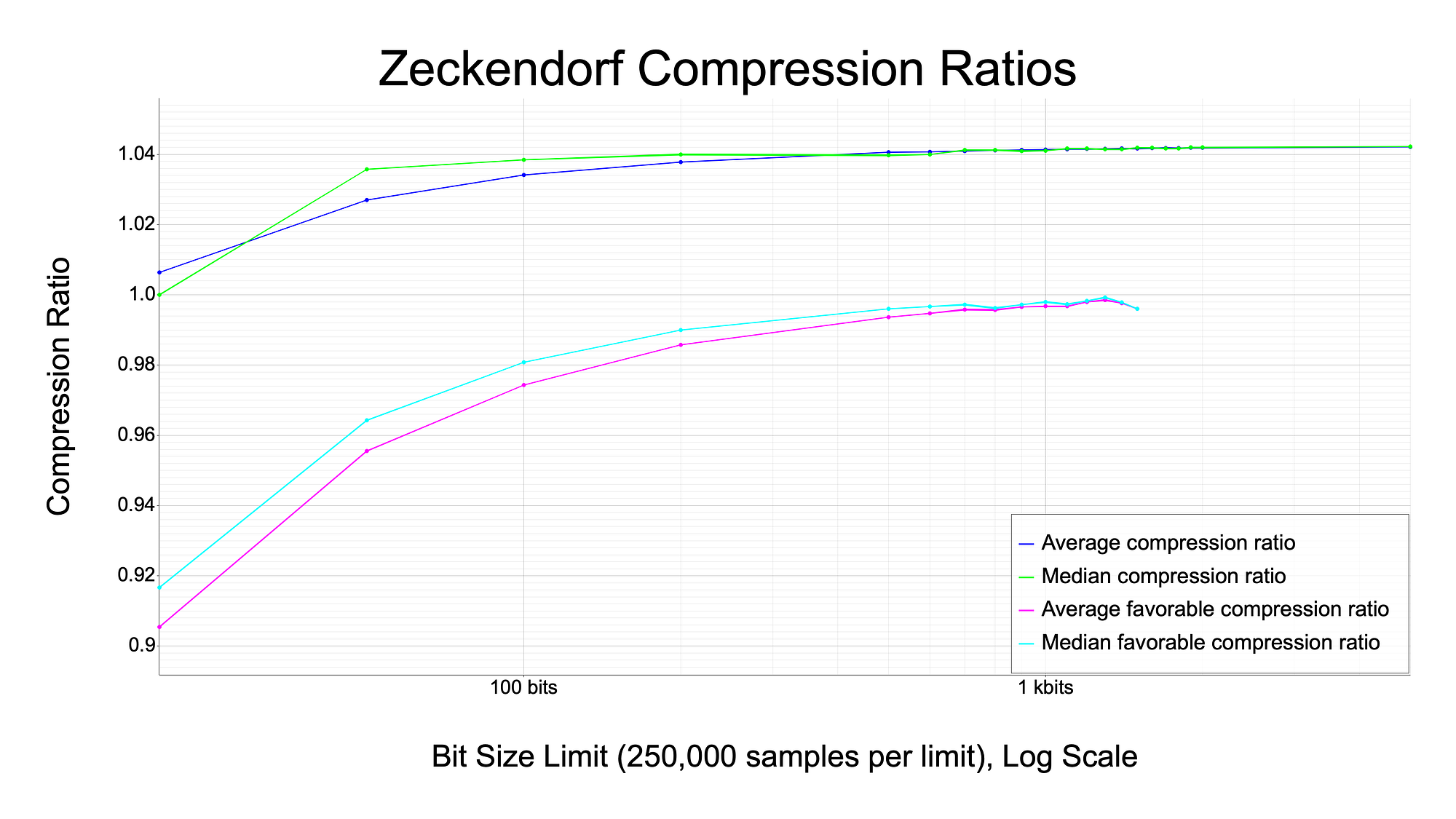
You can see that the “favorable” compression ratios converge to around 1.0 after 1 kbit, which agrees with the prior graph showing the odds of compression being favorable. But the median and average “compression” (maybe “transformation” is a better term here because the size of the data tends to increase) tends to approach on the order of 1.042, meaning that on average, arbitrary data that is transformed by the Zeckendorf compression algorithm gets larger by about 4.2%.
There will naturally be outliers in these graphs at “All Ones Zeckendorf Numbers”, which is the degenerate case where all the bits in the Zeckendorf representation are ‘1’. But again, this is extremely rare for a piece of data to fall on or near those numbers, so it is difficult to see them in the graph. But there is potential for optimization if the input data could be slightly “massaged” to be nearer to an “All Ones Zeckendorf Number”. I go over that more in the next section.
Further Compression Algorithms and Tweaks Related to Zeckendorf Compression
I can imagine there is a lot more work to be done in figuring out more optimal and efficient algorithms based on this work. I will enumerate a few possible directions.
“All Ones Zeckendorf Numbers”
Whenever there is a “Zeckendorf Bits” list that is composed of all “use bits” or “1’s”, then this number is able to “reach” out to higher numbers faster than binary. For example, let’s look at “1111”. In binary, this represents the decimal number 15 by summing 1 + 2 + 4 + 8 (or by doing 2⁴ — 1). But if we interpret this as four Zeckendorf “use bits”, we get 1 + 3 + 8 + 21 which equals 33, a number quite a bit larger than 15.
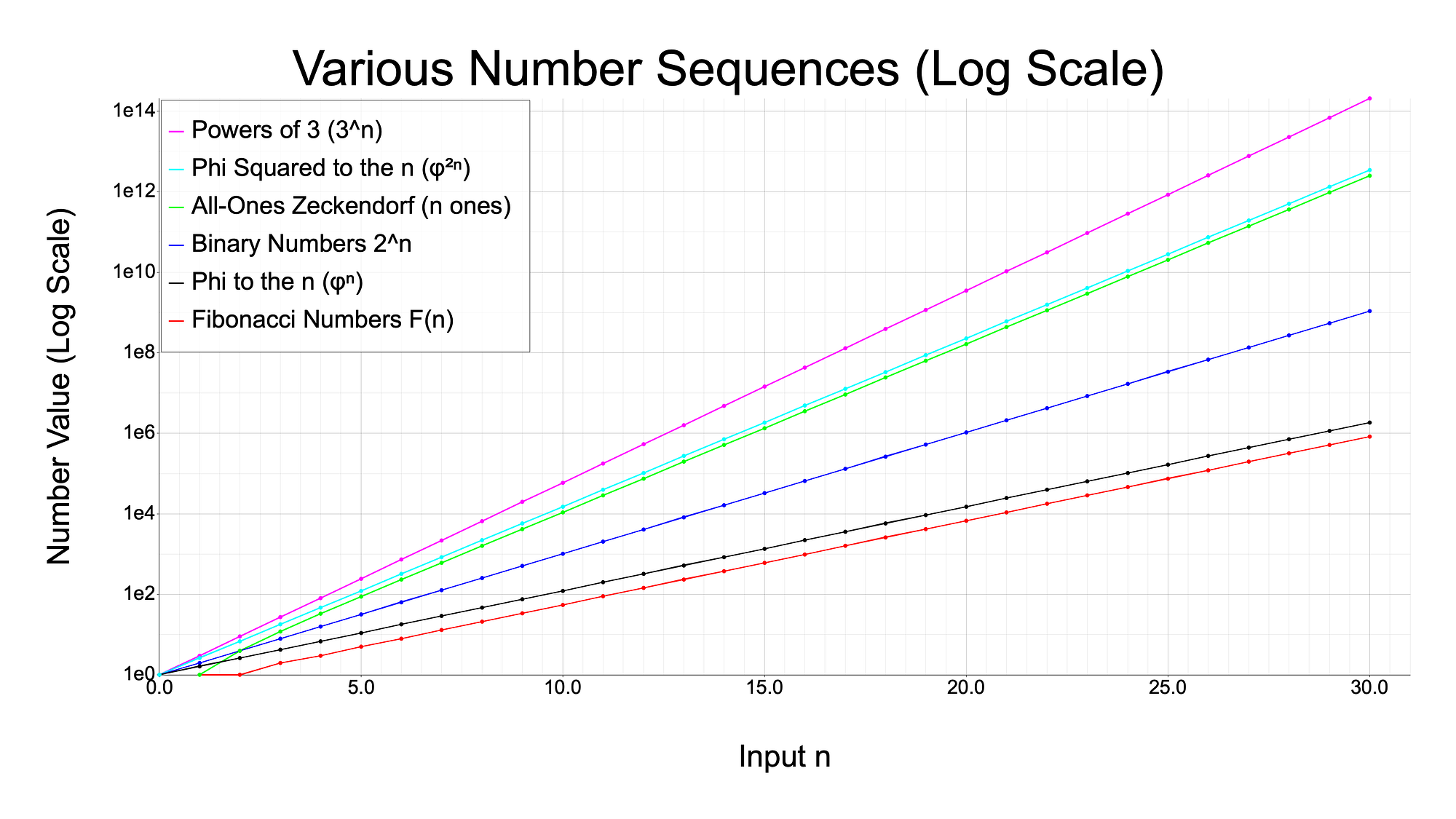
Below is a graph comparing the growth rate of “all ones Zeckendorf numbers”, or AOZN’s for short, to the Fibonacci numbers, binary numbers (2^n), and powers of 3 (3^n). And interestingly, I found a relation between the growth of Fibonacci numbers and powers of the golden ratio (φ, or 1.618…), as well as a relation between the AOZN’s and powers of the golden ratio squared, φ²: namely, these pairs of sequences grow at the same rate, just offset by some constant factor. You can easily see these pairs have very similar slopes in the graph.
If we consider a “lucky” example, let’s suppose we want to compress a file that happens to be not too “far” from one of these numbers represented by an AOZN. For example, let’s say our data was equal to a number equaling 100k ‘1’ Zeckendorf bits plus 1k arbitrary bits. As raw data, summing 100k Zeckendorf Use Bits produces a number that takes about 138k bits to represent in binary. With this, we can represent our 138k of data with two pieces of information: the count of ‘1’ bits in the AOZN and those arbitrary 1k bits. Since there are 100k one bits, we can just represent this part with the number 100,000. The number 100,000 only takes roughly 17 bits to represent (log2(100,000)). So we can specify a file format that is the combination of these two pieces of information, which only needs roughly 1k bits plus 17 bits. So we have effectively compressed our data from 138k bits to about 1k bits, a 99% reduction. This seems great, but the catch is that it is extremely rare for data to be “near” an AOZN. In general, most numbers are far enough from an AOZN such that it takes roughly the same number of bits added to that number to produce the target data, which results in no savings.
Chunked Preprocessing
Since we figured out that the odds of any compression happening past 1,000 bits falls off a cliff, what if we first chunk the input at like 500 bit chunks, so that every chunk has a somewhat higher chance of being compressed?
Immediately, I can think of a few issues with this approach. Namely, how does the decompressor know how big the chunks of data to decompress are? We will now need to store additional information about the chunk sizes somewhere, perhaps in a header. But that now reduces the compression efficiency.
For an example, let’s say we chunk some data at 100 bit chunks, which has a 10% chance of being compressed at a median of ~2.5% savings. Then each chunk will only be saving less than 1 bit on average. And for representing bit sizes up to 100 bits, we will need log2(100) bits or 7 bits per chunk to tell the decompressor how many bits to read per chunk. Dang. This method will likely not be useful.
Only Compress Data Sets Between 100bits — 1kbit
This is a similar strategy to the Chunked Preprocessing, except that we are only considering individual files that are less than than 1 kbit. The benefit here is that we don’t need to explicitly store extra data in order to recombine chunks; the operating system could store the true file sizes, which I believe it already does.
Doing similar math to the chunked preprocessing, if all your data is around 100 bits each, and there is a ~10% chance of compression at a median of ~2.5% savings, then you can expect your data set to be reduced in size by about 0.25%. Unfortunately, that is not a very impressive number. But at a large scale, this could theoretically produce some savings.
Lossy Zeckendorf Compression
There might be other ways to compress the data in a lossy manner, using the Zeckendorf algorithm as a base. I could imagine there being methods of preprocessing the data first, with something like a Fast Fourier Transform or a Discrete Cosine Transform (used in JPEGs), and massaging the data to fit into more compressible Zeckendorf numbers, as mentioned in the “All Ones Zeckendorf Numbers” subsection.
Compositions with Other Compression/Coding Algorithms
Even though Zeckendorf compression may not be useful in and of itself, it could be used in conjunction with other compression algorithms as a “last leg” if favorable.
This is analogous to how Huffman Coding is used, which, according to Wikipedia, is used as a “back-end” to other compression algorithms like JPEG and MP3.
If applying Zeckendorf compression is favorable for some file, then it just needs a singe piece of information in the resultant compressed file to signify that it was used, so that the decompressor know to decompress it. My compression utility, called zeck-compress, stores files with a .zbe or a .zle file extension, depending on if the input was interpreted as a big endian integer or a little endian integer.
Addition/Multiplication/XOR Then Compression
It is possible that there are “good numbers” to preprocess the input data with, which then produces data that is more compressible via Zeckendorf. If it does help, then the resultant compressed file just needs to store the operation, the “good number”, and the resultant compressed data to remake the original data (if the storage size of these three pieces of data happens to be less than the original input).
One strategy is to find the nearest AOZN to the data and then get the difference between it and the AOZN to know what number the decompressor needs to add to it. I did some testing with this method, but it is extremely unlikely for large pieces of data to be near AOZNs, and even if it is, the number to add it with is likely to take as many bits as the input data itself, which yields no data savings.
It’s possible that performing a division on the input data would be more beneficial, because the resultant data can be much smaller than with subtraction, with a similarly sized divisor. But this also will have diminishing returns because as the size of the divisor grows, the efficiency of the compression is reduced. I have not yet tested this method.
Then there is XORing the data, for which there could be a few different schemes. You wouldn’t want to store a piece of XOR that is as large as the input, otherwise, you’d need to store the whole thing in the result, which cancels the benefit of compression. Another scheme is to have a repeated piece of XOR data, which could be mirrored throughout the whole input, in order to reduce the size needed to store the XOR data. But this would be a costly operation, to search for many permutations of data to XOR with to find one that yields beneficial compression. I have not yet tested this method either.
There are likely other mathematical or bit operations I am not considering, but they may be useful here.
Inverted Zeckendorf
Since trying to “compress” data with Zeckendorf tends to produce more data than less, what if we treated the input data as already compressed and try to “decompress” it with the thinking that, since probabilistically most compress actions produce larger data, maybe decompress actions produce smaller data.
Unfortunately, this doesn’t work. If you think about it, if we take arbitrary data, and treat its bits as a list of Zeckendorf “use bits”, then summing over those bits by converting them to Fibonacci numbers will tend to yield, on average, a larger number than simply interpreting the input as binary. Therefore, this is likely not a useful avenue for compression.
AOZN List
What if we represented our data as a list of AOZN indices? Since AOZNs can reach out to larger numbers faster than powers of two, this could be a new numbering system essentially. And perhaps utilizing skip bits could work here as well.
Well, looking into it, the first handful of elements of the sequence of AOZNs is 1, 4, 12, 33, 88, 232, 609, 1596, 4180, 10945, etc. Already, we can see one issue: the gap between the first two elements (1, 4), means that we would need 3 bits of information to represent the number 3, or any other number where 3 was the remainder after subtracting other AOZNs. That’s not great. And subsequent gaps mean we may subsequently need multiples of other elements to represent other numbers. I have not tested this method further.
Further Related Areas of Research
Circuits / Hardware
If the Zeckendorf representation turns out to be useful for certain applications, then it might make sense to produce hardware optimized for dealing with the Zeckendorf representation. Or, it’s possible that certain operations on hardware execute faster when dealing with the Zeckendorf representation versus binary representation. Some operations that would be interesting to test are all of the basic numeric operations like addition, subtraction, multiplication, division, etc. I have not tested this yet.
And since the Zeckendorf compression and decompression algorithms involve determining extremely large Fibonacci values, it might be worth it to have lookup tables in hardware, for hyper fast lookups. It would be interesting to investigate the performance of having a sped up Zeckendorf codec in terms of time and cost savings with specialized hardware.
Other Numbering Systems
What about using a numbering system based on other sequences, like prime numbers? Could that work in compressing data?
A cursory glance at this reveals that it does not quite have the same properties as a numbering system based on Fibonacci numbers. I mean, there is the Fundamental Theorem of Arithmetic, which states, somewhat analogously to Zeckendorf’s Theorem, that all integers greater than 1 have a unique representation of products of prime numbers. But it is not as clear as to how to represent this using 1’s and 0’s, while saving data. Maybe someone more clever than me can take a crack at this…
“Poorly Compressible Numbers”
Since we have the idea of AOZN’s being “well compressible”, what would the opposite look like? Well, that would be a string of 0 bits, and then a 1 bit, to “use” a Fibonacci number. The reason for this is that by using mostly 0’s, we do not save any data that we would have saved by using 1 bits and skipping Fibonacci numbers. When we have a large string of 0’s and then a 1, this is basically equivalent to indexing a specific Fibonacci number. It’s like a “Fibonacci selector.”
For example, if we have the bits 100, this can be interpreted as 1*F(2) + 0*F(1) + 0*F(0) which is 3, which is the third “effective Fibonacci” number or the fifth “actual Fibonacci number”. I use the term “effective”, since, like in Fibbinary, we skip the first two Fibonacci numbers which are 0 and 1; 0 does not help us and 1 is redundant to the second Fibonacci number. An “effective” Fibonacci number is just two Fibonacci numbers forward. So the third effective Fibonacci number is 3, (1, 2, 3, 5, 8, 13, …).
AOZN Compressibility
What makes AOZNs so compressible? I think one thing that makes it special is that it is a special case of Zeckendorf bit lists, which can be thought of as a variable bit length encoding. Some larger numbers take fewer bits to represent than some smaller numbers, and all numbers are uniquely representable. I think that is a fascinating property; I’m not sure if there are other sequences that have that property. It’s like getting more for less, and losing nothing. I would surmise that there are other sequences that can mimic these properties, but I can’t fathom another consistent way having larger numbers taking less space than smaller numbers, simply by using a different numbering system.
The manner in which the Zeckendorf bit list is a variable bit length encoding is such that whenever we see a 1 bit in the list, we “skip” the next Fibonacci number. And since we don’t need to store those unnecessary 0s, we save on data. In this way, it reminds me of a skip list, which is a data structure that, similarly, skips the traversal of elements at certain locations when doing a search. Perhaps we could think of different kinds of skip lists for Fibonacci numbers, based on properties of the input data, which could save further data. My Zeckendorf algorithm can be thought of as the first-order skip list for representing numbers. But there could be other schemes that skip more than one index at a time, if that is made clear in the algorithm. And since not all numbers could be representable by skipping more than one index, that could be another example of a lossy compression, since some data would need to be compressed at the nearest possible representable string of bits. Further investigation is needed here.
Other Things
Has this been done before?
As far as I could find, this method has not been done before. I find it funny that I could not find prior examples. I’d think that someone would have thought of this before, since it’s so close to Fibbinary. Maybe it is out there somewhere but was shelved as an impractical system. Either way, I’m sure someone will reach out to me to point out that this was a known algorithm. Even if it was already known, at least I had fun developing it, and I hope we could find something useful from this research.
Did you use AI?
I, Peter Ryszkiewicz, came up with this idea roughly 6 years ago, before ChatGPT was even released. I have private prototype code on GitHub in Typescript, that can be used to prove this, and GitHub could attest to the push timestamps since git histories can be faked. But the code is old and ugly so I’m choosing not to publicize that. That being said, the recent implementations in Rust and the web application did use AI assistance (Cursor and Lovable mostly).
Screenshot of my old prototype for Zeckendorf encoding
Did you use AI to write this article?
No, I decided against using AI for this article so that my writing style could be expressed faithfully. I also don’t like the writing style of AI, because even though it is usually very clear, it tends to be tasteless and soulless; a chopped salad of all the labor of all the great authors who have lived and died before us. I don’t like that. When you read this article, you are actually getting a taste of what goes on in Peter Ryszkiewicz’s personal neural nets 😄😁
Ironically, after publishing this article, I ran it through some AIs and it pointed out a number of interesting things, including some mistakes. Subsequently, I have fixed the mistakes in this article and I will post another article detailing the interesting findings, shortly.
Addendum
All plots were made with the Rust library plotters, and all code for generating the plots are available on my repository at https://github.com/pRizz/zeckendorf/blob/main/src/bin/plot.rs.
Code for generating the dark mode compatible LaTeX formula images is available at https://github.com/pRizz/zeckendorf-article.
The Rust crate is published here: https://crates.io/crates/zeck
The npm library is published here: https://www.npmjs.com/package/zeck
The demo app is published here: https://prizz.github.io/zeckendorf-webapp/
The source code for the reference implementation is here: https://github.com/pRizz/zeckendorf. PRs welcome! Lots of hard work is needed to optimize the performance and memory pressure of compressing and decompressing!